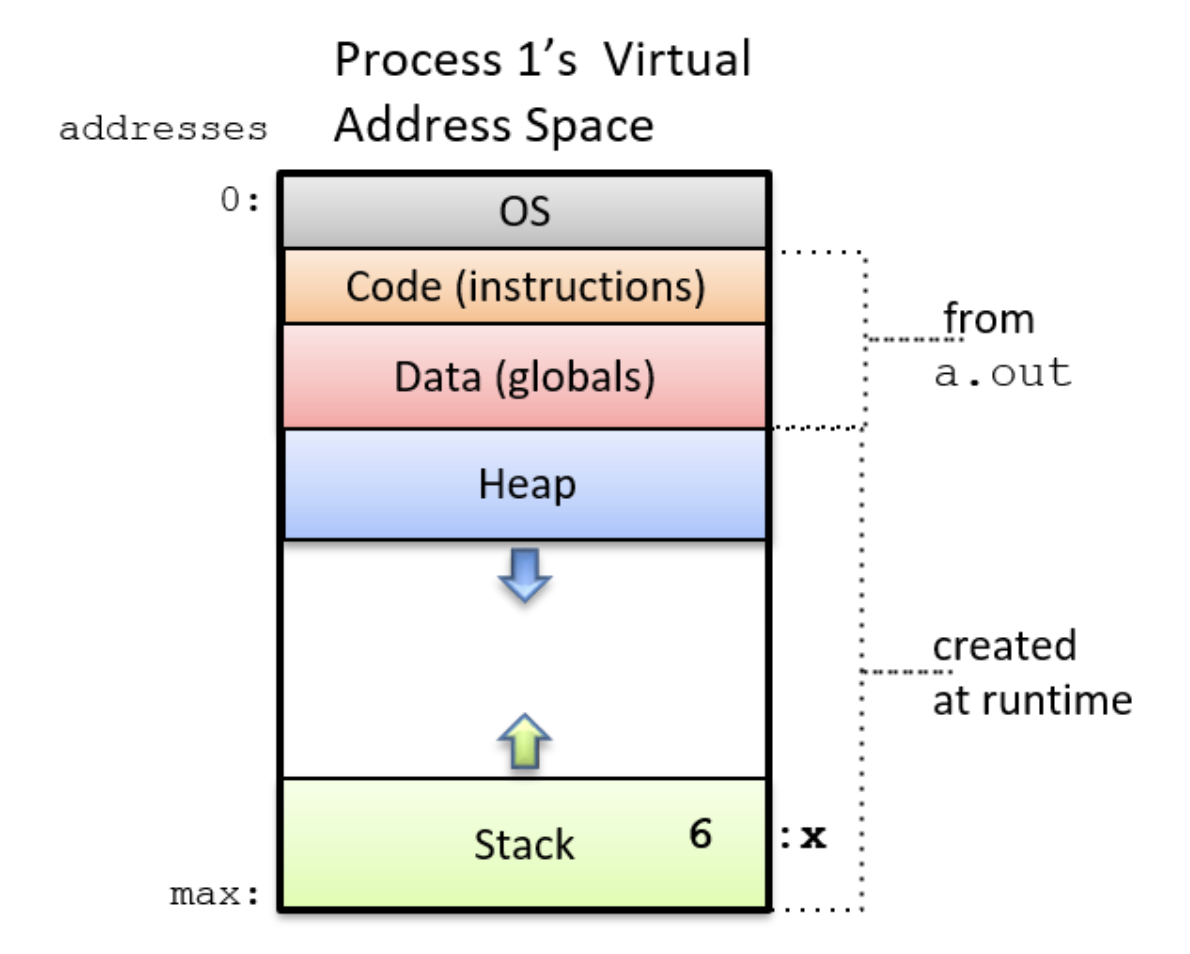
A list of memory locations from 0 to some maximum, which Process (进程) can access
Address space is powered by Virtual Memory, so everything in address space is dedicated to that particular process
4 main components
Data in Text Segment (the orange block shown above) and Data Segment (the red block shown above) are shipped with the program
Data in Heap Segment (the blue block shown above) and Stack Segment (the green block shown above) are allocated dynamically when the program is running
Heap Segment
Dynamically allocated region where the Process (进程) can create new data structures as needed
Grows and shrinks as the process allocates and deallocates memory
Grow upwards
Region of Virtual Memory where data can live indefinitely even when function returns
Require manual memory management from the process - process of allocating memory and deallocating memory. See language examples below
When assigning one variable to another variable, data is not duplicated, instead the Pointer to the data is duplicated and assigned
A nice visualisation on memory allocation can be found here
Java
Memory allocation with new keyword, and memory deallocation is done by Garbage Collector automatically
Rust
Memory allocation with Box::new() function, and memory deallocation is done automatically using Box Deallocation Principle
C
Memory allocation with malloc() function, and manual memory deallocation is done with free() function
Manual Memory Deallocation is Dangerous!
After we manually deallocated the heap memory associated with a Pointer, then try to read data from the same pointer, it will lead to undefined behaviours. Thus, resulting in Poor memory safety
Data management in Stack Segment is more efficient than Heap Segment
Stack memory is allocated and deallocated in a Last In, First Out (LIFO) manner, making it faster than heap memory. This is because all it needs to do is move the Stack Pointer up or down, while heap memory requires more complex memory management
No overhead of complex Synchronization (同步), unlike data inside heap segment, data inside the stack segment is usually dedicated to that particular Process (进程) or Thread. Thus, manipulation of data inside the stack segment doesn’t require the complex synchronisation
Stack Overflow
Happens when the size of all the stack frame is over the default fixed size of the stack segment
XV6-RISCV Kernel Stack
// xv6-riscv kernel codes, start.c#include "types.h"#include "param.h"#include "memlayout.h"#include "riscv.h"#include "defs.h"void main();void timerinit();// entry.S needs one stack per CPU.__attribute__ ((aligned (16))) char stack0[4096 * NCPU];// a scratch area per CPU for machine-mode timer interrupts.uint64 timer_scratch[NCPU][5];// assembly code in kernelvec.S for machine-mode timer interrupt.extern void timervec();// ...
A stack segment is created, and it is shared by all the CPU, each takes 4096 bytes
NCPU is hard-coded to 8, so the stack has a length of 32768 bytes
# xv6-riscv kernel codes, entry.S# qemu -kernel loads the kernel at 0x80000000# and causes each hart (i.e. CPU) to jump there.# kernel.ld causes the following code to# be placed at 0x80000000..section .text.global _entry_entry: # set up a stack for C. # stack0 is declared in start.c, # with a 4096-byte stack per CPU. # sp = stack0 + (hartid * 4096) la sp, stack0 li a0, 1024*4 csrr a1, mhartid addi a1, a1, 1 mul a0, a0, a1 add sp, sp, a0 # jump to start() in start.c call startspin: j spin
We load the base address of the stack segment
Then based on the core id (0-7), we set the Stack Pointer for each CPU. We can see the stack pointer starting point is obtained by adding (hartid * 4096) to the base address, this is because stack segment grows downwards when we are adding values to the stack
Data Segment
This region stores global and static variables and constants used by the program, pre-defined before the execution of the program
Can be both read and write, allowing the Process (进程) to manipulate the data as needed